1、简介
主要用于数据处理、转换、迁移的工具。
是一款国外开源的ETL工具,纯Java编写。能够直接运行在Windows、Linux、Unix上。允许管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
kettle中的两种脚本文件
- transformation(转换)
完成数据基础转换(数据流)。一次性启动所有控件,且一个控件对应一个线程,然后数据流从第一个控件开始,一条记录、一条记录地流向最后的控件。
- job(工作)
完成整个工作(步骤流)流控制。作业的每一个步骤,必须等待前面步骤的完成,后面才会执行:
2、流程
转换

作业

3、核心组件(windows:bat,Linux:sh)
- 勺子(Spoon.bat/.sh):是一个图形化页面,可以让我们用图形化的方式开发转换和作业。
- 煎锅(Pan.bat/sh):命令行形式执行由Spoon编辑的转换和作业。
- 厨房(Kitchen.bat/sh):命令行调用Spoon编辑好的Job
- 菜单(Carte.bat/sh):轻量级的Web容器,建立专用远程的ETL、Server。
4、快速上手
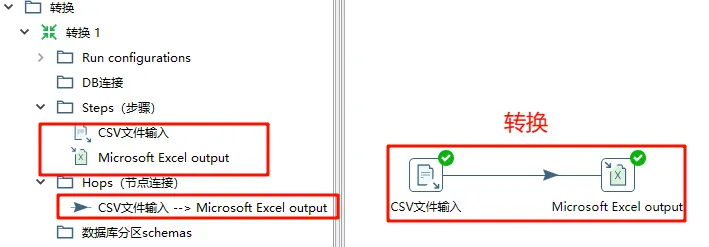
转换
执行操作:将csv文件数据输出位Excel数据
建立控件,将转准备好的csv数据选中为该组件文件名
注:修正4步骤中分隔符为英文字母“,”。否则无法预览字段
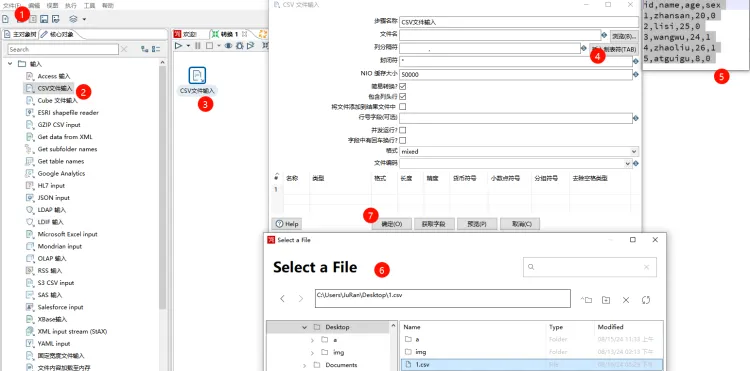
同时加入excel文件输出控件(链接快捷键(shift + 鼠标键拖动))。

双击输出控件配置输出excel相关路径。
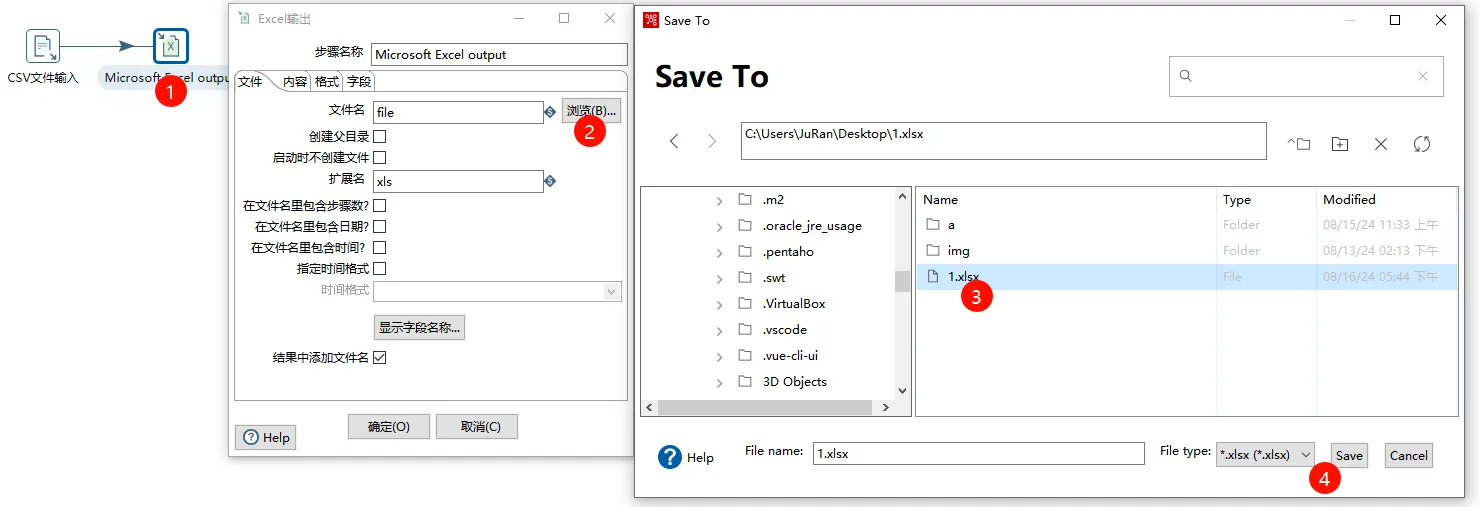
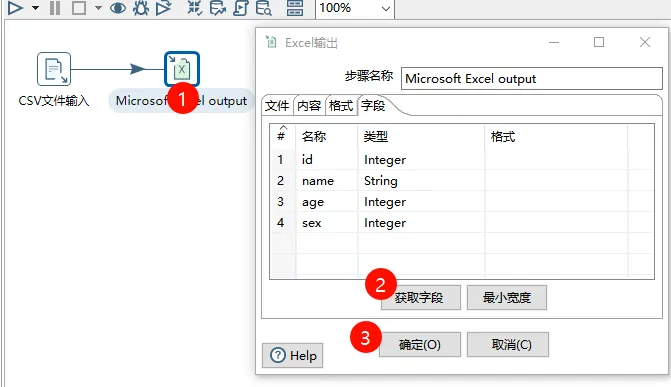
紧接着查看是否能够读取csv中字段信息。
执行转换任务
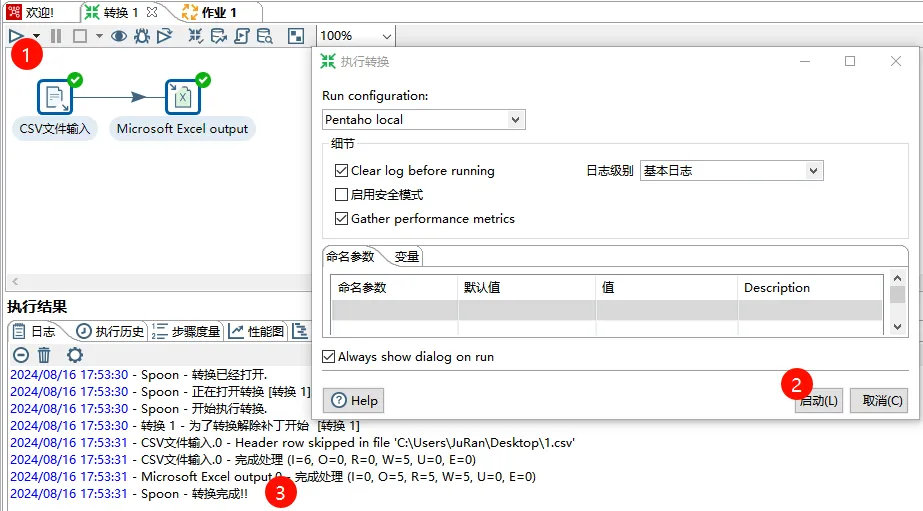
即可在输出位置查看相关转换完成的Excel文件。
2024-08-19 增加
5、核心概念
5.1 转换(transformation)
负责数据的输入、转换、校验和输出等工作。
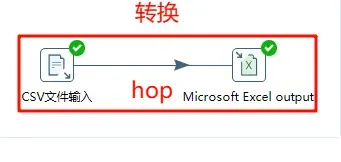
转换由多个Step组成(文本文件的输出、过滤输出行、执行Sql脚本等),各个步骤之间使用Hop进行连接。hop定义了一个数据通道,即数据由一个步骤流(hop)向下一个步骤。
kettle中最小单位是数据 行,数据流中流动其实是缓存的行集。
5.2 步骤(step)
步骤是转换中的基本组成部分,快速上手中(Cvs输入控件及excel 输出控件)都是指步骤。
一般特性:
- 同一转换范围内名称唯一
- 每个步骤都能够读、写数据行
- 步骤将数据写到与之连接的一个或多个输出跳,再从传送到跳另一端的步骤。
- 大多数步骤都可以有多个输出跳。一个步骤的数据可以设置为分发或者复制。
分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤。
5.3 跳(Hop)
跳实际上是两个步骤之间的行集的数据行缓存,行集的大小可以在转换的设置里定义。当行集满了,向行集写数据的步骤停止写入,直到行集里又有了空间。当行集空了,从行集读取数据的步骤停止读取,直到行集中又有可读数据行。
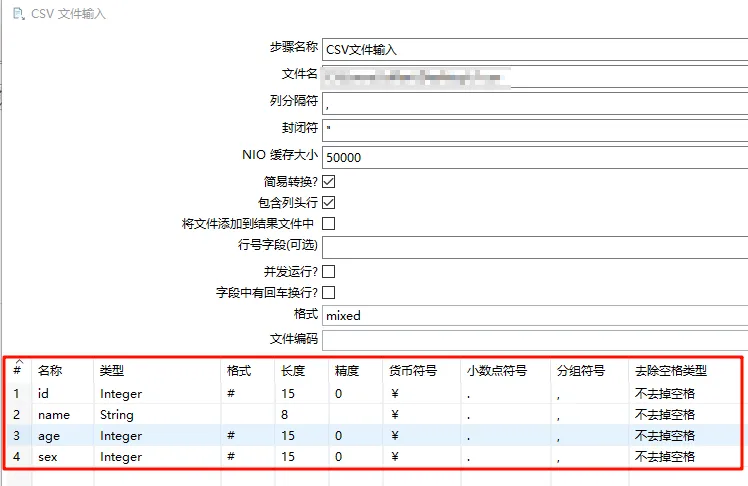
5.4 元数据
每个步骤在输出数据行时都有字段描述,这种描述就是数据行的元数据。
一些常见规则:
- 名称:数据行里的字段名是唯一的。
- 数据类型:字段的数据类型
- 格式:数据显示的方式,如Integer的#、0.00。
- 长度:字符串的长度或BigNumber数据类型的长度
- 精度:BigNumber数据类型的十进制精度
- 货币符号:¥
- 小数点符号:十进制小数点格式。不同文化背景下的小数点符号是不同的,有(.)有(,)。
- 分组符号:数值类型数据的分组符号,不同的文化背景下数字里的分组符号也是不同的,一般是(.)或(,)或(‘)。
5.5 并行
跳的这种基于行集缓存规则允许每个步骤都是由一个独立的线程运行。
高并发低消耗
这里并发程度最高,这一规则允许数据以最小消耗内存的数据流的 方式来处理。
对于kettle的转换,不能定义一个执行顺序,因为所有步骤都以并发的方式执行。
如果需要按照任务顺序执行,则需要作业。
5.6 作业
定义一个完整的工作流的控制。